当 30% 代码都由 AI 写出来,我们该把时间花在哪?
从「写代码」到「验代码」的三年实战笔记
2022 年,我第一次在生产项目里用上 VS Code 的 Copilot,用它来写一个再普通不过的后端接口:登录、校验、打点日志。
我刚给函数写好名字、入参和返回值,函数体还一行没写,编辑器底部就灰出来一整段代码:参数校验、错误码、日志风格,甚至连变量命名都和我平时写得差不多。
那一刻我心里只有一个念头:「AI Coding 好牛!」
两小时后,测试环境里一个边界场景直接 panic,把服务干崩,罪魁祸首正是这段看起来「标准又优雅」的自动生成代码。那晚我第一次很具体地意识到:AI 写代码最危险的地方,不是它写不出来,而是它写得「看起来对,其实不对」。
三年过去,到 2025 年,各大厂公开的数据和访谈里不断提到类似的数字:工程师新写的代码里,大约 20%–30% 已经是 AI 生成的,一些激进团队甚至做到 50%。
但很多已经上手 AI Coding 的工程师,包括当时的我自己,却有很相似的感受:写的代码变多了,背的责任更重了,人反而更累。
我叫厉辉,网名 yousa。在大厂写了很多年后端,也在开源社区混过几轮(当过 Apache 项目贡献者和 CNCF Ambassador)。从 2022 年开始,我几乎每天都在和各种 AI Coding 工具打交道:从 VS Code 里的 Copilot,到 Cursor、Windsurf,再到 Codex、Trae SOLO 这一类更「重」的 Agent。
这篇文章写给已经在或准备在真实生产项目里用 AI Coding 的后端 / 全栈工程师和技术管理者。
它不会教你「按钮在哪里」「哪个 prompt 最神」,而是想在大约 15 分钟里,帮你搞清楚三件事:
- 哪些任务交给 AI 最「划算」
- 怎么让项目本身变得更「AI 友好」,提高一次命中率
- 当生成不再是瓶颈时,工程师应该如何设计验证流程,把时间花在真正值钱的地方。
文中的例子主要来自互联网业务后端,但你可以类比到自己的技术栈。
从下一节开始,我们就从这三年里我听到的两种极端声音讲起,看一看这场「从写代码到验代码」的角色变化,是怎么一步步发生的。
一、两种声音,和我自己走过的弯路

围绕 AI 编程,大家常听到两种极端的声音。
一边是布道者:「太强了!我 5 分钟生成了 10 个单元测试,AI 是 10 倍效率工具,你不用是思想没跟上。」
另一边是怀疑论者:「就是个玩具。我花半小时 debug 它写的 Bug,还不如自己写。」
有趣的是,两边其实都没错,只是他们站在不同的场景里:
- 在新项目、简单逻辑、没有历史包袱的「快乐路径」上,AI 确实像开挂
- 一旦落到复杂业务、遗留系统、技术债堆积的真实世界,它又经常「看着对,其实不对」

我刚开始用 AI 的那一年,基本就在这两种状态之间来回横跳。我当时的策略很简单:到处随手一试,哪怕完全是随机试错:
- 看到一个任务,直觉觉得 AI 能做,就丢给它
- 成功的时候很惊喜,失败的时候很沮丧
- 一圈下来,发现成功靠运气,经验没法复制,更别谈规模化了
这有点像很多团队刚接触自动化测试的阶段。随手录几个 UI 脚本,一挂就全挂,然后很快得出结论:「自动化没用」。真正的问题不是工具,而是我们没想清楚到底要让它干什么。
二、别再问「准不准」,先算「值不值」
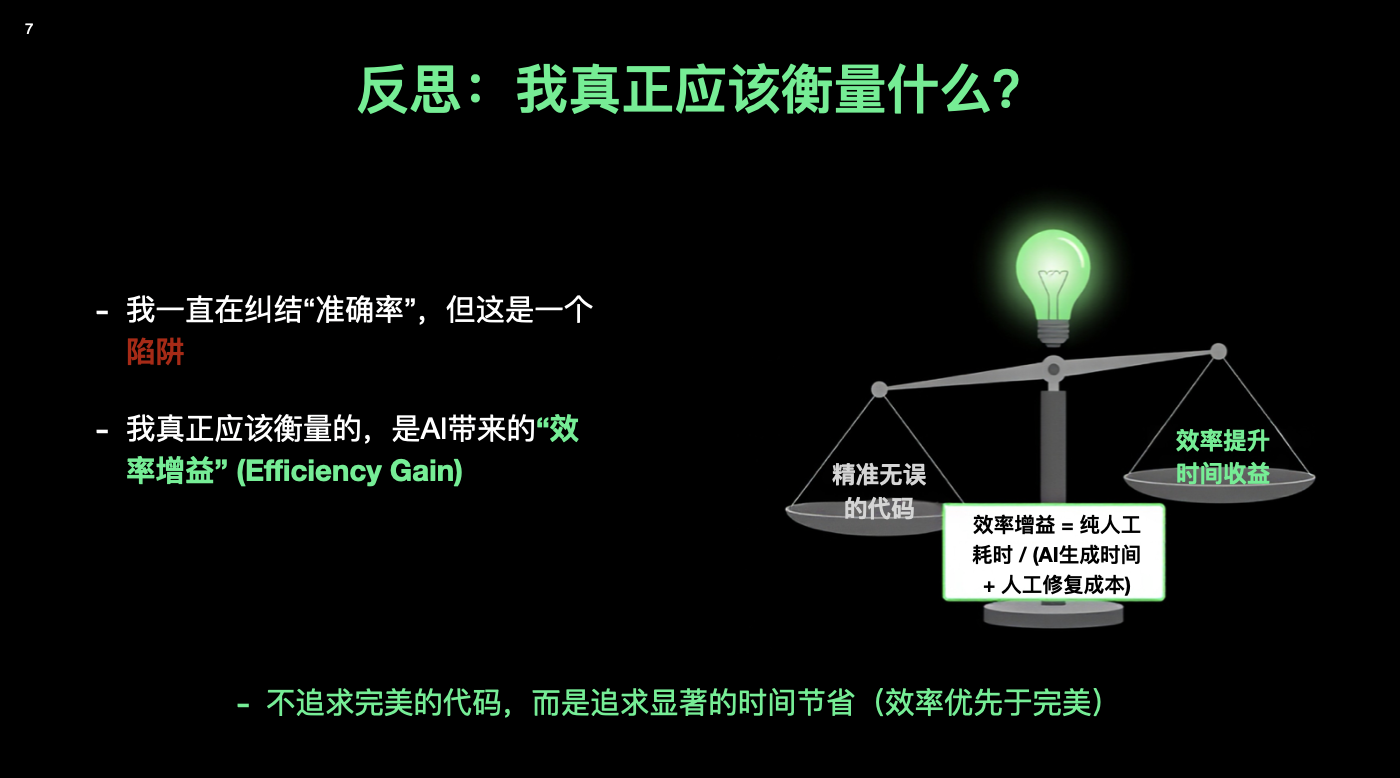
我花了很长时间,才意识到自己被一个词绑架了:准确率。每天我想的都是:「它写的这段对不对?」「有没有 Bug?」「能不能一次生成就通过?」
如果只从「准不准」来评估,结论永远是:还是我自己写更放心。
但在真实项目里,我们真正应该算的是另外一条式子:
效率增益 = 纯人工耗时 ÷(AI 生成时间 + 人工修复时间)
翻成白话就是,如果我自己写要 8 小时,AI 帮我生成用了 30 分钟,我再花 1 小时改一改,那我其实是用 1.5 小时,干完了原来 8 小时的活。代码不用完美,只要划算。
「甜点区」的四个特征
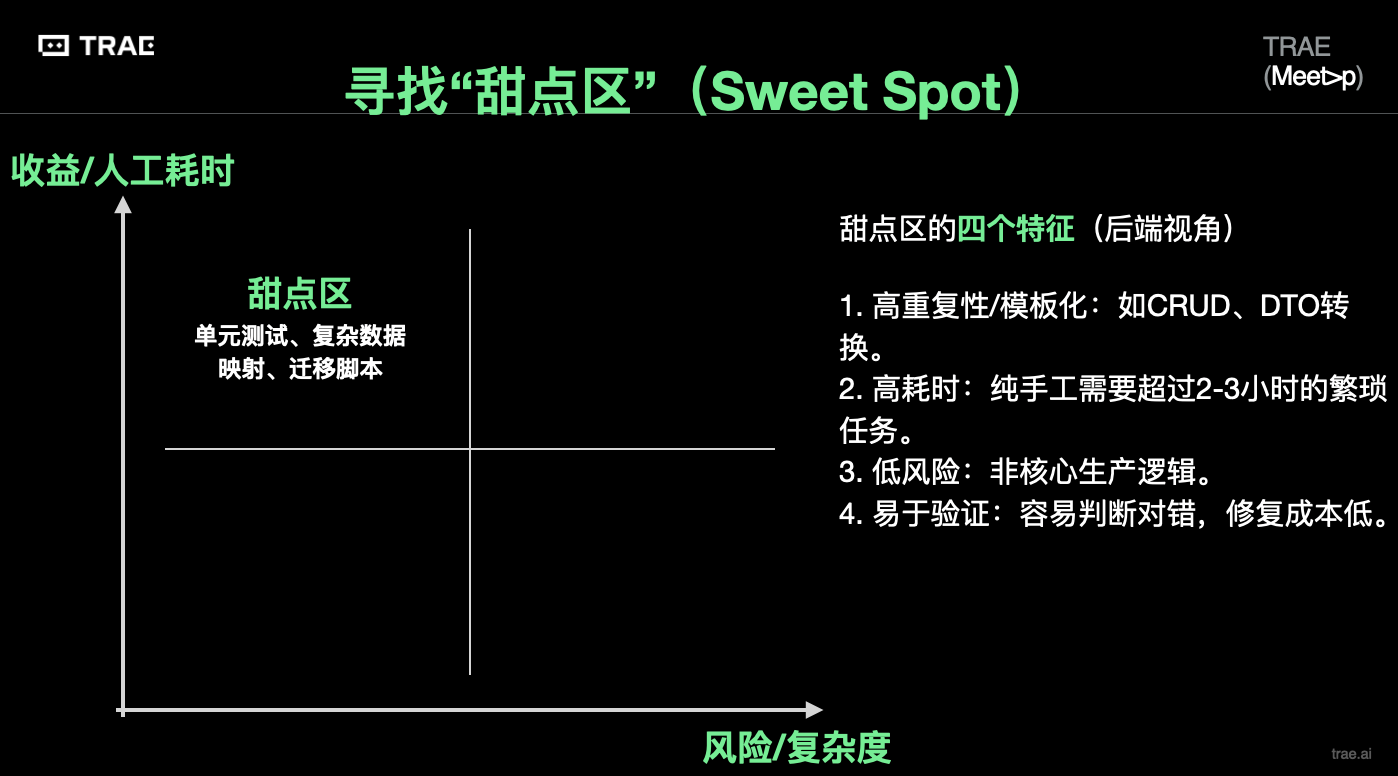
于是我开始认真观察:到底什么任务交给 AI 最「划算」?
从后端视角看,我最后总结出了一个「甜点区」:
- 高重复 / 模板化,典型就是各种 CRUD:创建、查询、更新、删除接口,还有重复的校验逻辑、分页查询、条件组合过滤等。
- 高耗时,纯手写要磨 2–3 小时以上,但创造性不高。
- 低风险,不是一改错就会把核心业务搞挂的地方。
- 易验证,验证条件清楚:要么能快速写出测试脚本,要么肉眼就能看出来对不对。
这类工作,说白了就是「不得不写,但写了也没什么成就感」的那一块。AI 很擅长干这种活。
把「一天的 CRUD」压缩到「两小时」
举一个更接地气的例子。有一次,我们需要为一个内部系统写一批接口。大概有十几个实体,每个实体都要配一套完整的 CRUD 接口,再加上基本的鉴权、错误码、分页查询和简单筛选。
旧办法:熟练工程师也要一整天
如果按传统方式来搞,大概是这样的节奏:先把所有接口在脑子里捋一遍,写一份大致的接口设计文档,再逐个去写 Controller、Service、DAO,写完再补测试脚本和一点点文档。一个熟悉业务的工程师,基本要花掉一整天。
新办法:先写样板,再批量复制
- 先自己手写一个「标准答案」,选一个最典型的实体,花半小时认真写一套最满意的 CRUD:包含路由结构、错误码风格、日志规范,把请求 / 响应结构写清楚,顺手在仓库里加一个
Agent.md,解释这个模块的分层结构、命名约定、异常处理习惯。 - 把这份标准答案「喂」给 AI,当成 few-shot 示例,用非常直白的话告诉它:「后面所有实体,都按照这个风格来,目录结构照抄,错误码和返回体也照这个约定扩展」。
- 让 AI 批量生成剩下十几个实体的 CRUD,这一步大概只要二三十分钟:提示写好后,它可以很快把 Controller / Service / Repository 扫一遍输出。
- 再用一个小时做人工梳理:手动把体感不舒服的命名改掉,写两三个通用的集成测试,跑一下最容易出错的路径,最后再用 AI 帮你生成简单的测试脚本和 curl / httpie 示例,顺带写点文档。
算一笔总账
最后的账是这么算的:以前:1 天;现在:半小时写模板 + Agent.md / Spec,30 分钟让 AI 批量生成,1 小时仔细校正和写测试。总计差不多 2 小时,节省了 6 小时。
你要是盯着准确率看,会觉得它一开始生成的代码漏洞不少。有的条件判断顺序不对,有的错误码命名你不喜欢。但从「值不值」这个角度,它已经非常值了。
顺带一提,这是一个简单但很好用的小技巧:
先认真写一个你最满意的样板,再让 AI 批量模仿,而不是一上来就让它凭空发挥。
心态的拐点:从「单点完美」到「系统可靠」

在这里,其实有一个更重要的心态变化。早年的后端世界,大家追求的是「单机极致可靠」:买一台 IBM 大型机,硬件质量、机房环境、运维流程都做到极致,希望这台机器永远不要挂。后来互联网规模上来了,这套理念撑不住了。像 Google、Amazon 这些公司开始做分布式系统,默认前提变成:
「单机总会挂,但系统不能挂。」
于是有了 CAP 理论,有了各种副本、选主、心跳检测,有了 Dynamo、GFS 这一大票系统设计。我们接受了单点会失败这件事,把精力放到系统级兜底上。
我在用 AI 写代码时,自己的心态也经历了一个类似的转换:以前:追求「每次生成都得对」,一旦出现 bug 就怀疑这玩意是不是不靠谱。现在:接受「它本来就会犯错」,重点是看我能不能用一套流程,把这些错误控制在可接受范围内,同时把效率拉上去。换句话说,从追求「生成的准确率」,到设计「整个协作系统的效率」。

这个时候,一个对我非常有用的比喻是:把 AI 当成一个「能力很强、但完全不了解你项目背景的实习生」。它的「算法水平」可能比大多数同事都强,但一上来对你的业务、代码风格、一堆历史坑完全没有概念。如果你只丢一句「帮我写个登录」过去,本质上就是在期待它读心。
换成人类协作,你一定会先做几件事:
- 把现有流程讲清楚(包括失败分支、异常处理)
- 指给 TA 几个写得最标准的示例
- 说清楚「有哪些是绝对不能做错的」红线
对 AI 也是一样:你给它的上下文越像一份写清楚的「任务说明书 + 示例 + 约束」,它的输出就越像一个靠谱实习生,你越是只给一句模糊需求,它就越像一个会胡诌的诗人。

这里还有一个很容易踩的坑:用了 AI 之后,下意识觉得「AI 写的代码看起来很不错,快速 Review 之后觉得应该没有问题,LGTM」。但现实恰恰相反:AI 往往会生成大量看起来正确但实际上充满错误的代码,你必须为 AI 生成的每一行代码负责(包括它带来的事故)。
所以我给自己定了一条很反直觉的规矩:
对于 AI 写的代码,要比自己写的代码更不信任。
编译能过不代表能上线,能跑通一条 happy path 更不代表安全。对 AI 的产出,我默认要多做几件事:能写测试就写测试,至少覆盖边界条件;看一眼日志、监控,确认没有明显的异常模式;对关键改动多想一步「最坏会发生什么」
久而久之,我自己的工作重心也发生了结构性变化:过去:大概 80% 时间在写代码,20% 在自测和验证。现在:大概 30% 时间在定义任务、喂上下文、指挥 AI 生成,70% 在严肃地验证结果,写测试、跑脚本、读日志、看监控
你可以把这理解为,从「亲自写每一行实现」转向「更像一个定义需求 + 把关质量的总工程师」。不一定更轻松,但更贴近工程价值真正所在的那一层。我觉得这会是 GenAI 时代工程师绕不开的一个心态拐点:
接受随机性,把精力放在设计流程、验证机制和上下文,而不是纠结每一行是不是它一口气写对。
三、让项目变得「AI 友好」:标准化 + 自动化
前面我们讲的是个人层面的甜点区。往团队视角一拉,会发现一个更有趣的现象。

在我演讲的 PPT 里,放了几组公开数据:比如 GitHub×Accenture 的企业实验、安全公司 Aikido 的调研等等。大致结论是:
- 许多主流企业里,新增代码中 20%–30% 是 AI 写的
- 一些激进团队可以做到 50% 左右
- IDE 里 AI 自动补全的建议,大约 30% 会被开发者接受,而绝大部分会保留到最终版本
听上去已经不少了,但很多团队的主观感受是:一个常见的悖论:AI 用得多,效率却没明显提高
「我们用了 AI,为什么整体效率没有飞起来?」

我自己的体会是,在一个文档缺失、代码年久失修的项目里,AI 经常「看起来很对,其实不对」,幻觉特别多;在一个分层清晰、接口规范、测试完善的项目里,AI 写出来的东西,一次通过率就高很多
正如图中那样,左边是「祖传代码,请勿乱动」的小破屋,右边是有 Spec、有测试的现代大楼,Garbage in, Garbage out。
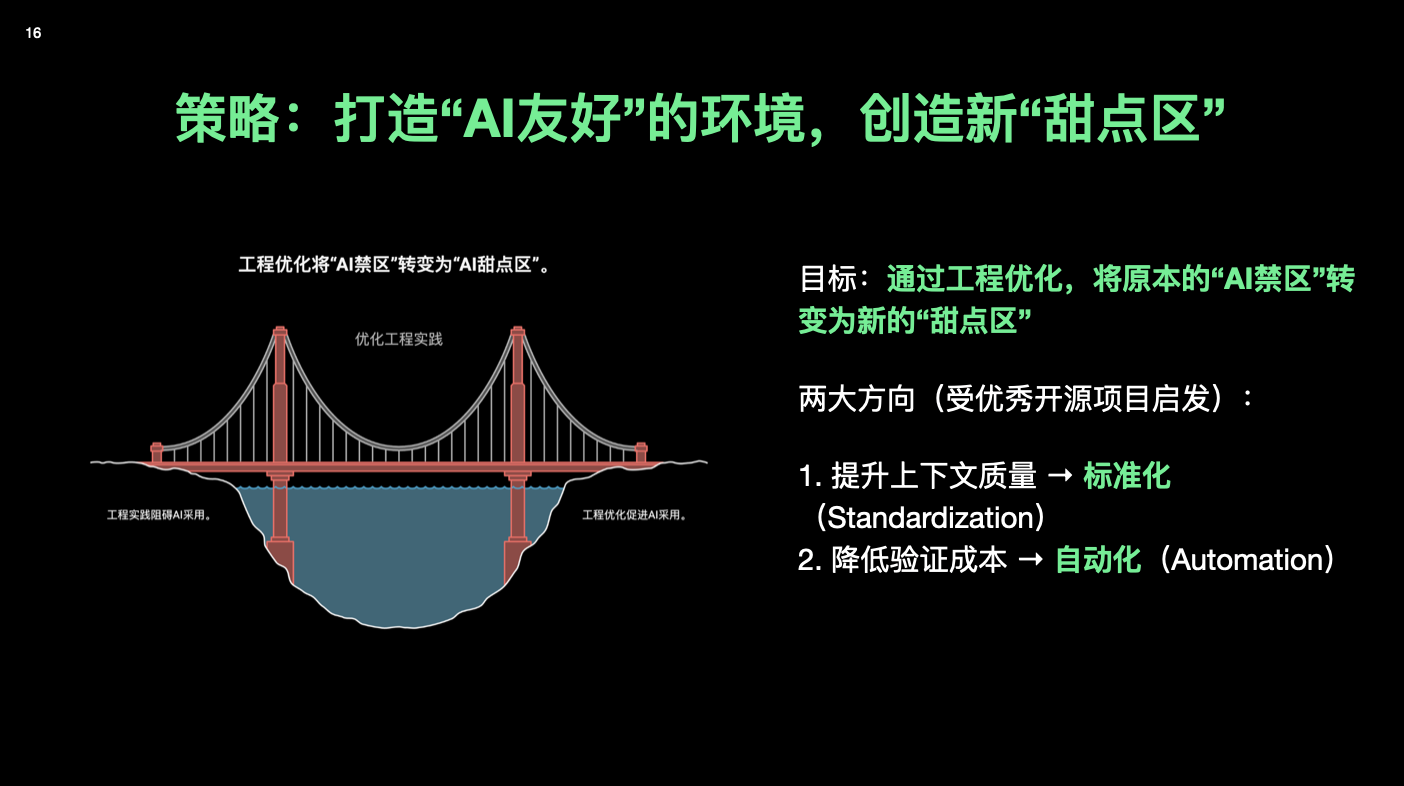
当你把那 20%–30% 的低垂果实摘完后,再往上走,靠的往往就不是换一个更大的模型,而是:让项目整体变得更「AI 友好」。 我把它拆成两件事:标准化 + 自动化。

1. 标准化:给人和 AI 都写一份「说明书」
标准化是提高上下文质量。
- 接口要有统一的规范(OpenAPI / Proto)
- 领域术语要收在一个地方
- 重要的业务规则写成正式的设计文档,最好能和代码关联起来
- 给新模块留一个最小可运行的 demo
这些在很多团队里听上去很「老生常谈」,但在 AI 时代有了一个新含义:
它既是给新人看的说明书,也是喂给 AI 的「高质量上下文」。
更妙的是,你不一定要「纯手工」写完这些说明书。以前说「补文档」,大家脑海里的画面是:一个资深同学坐在那,对着几万行祖传代码,一字一句写设计说明,一个月写不完。
现在的做法可以是:
- 让 AI 先读代码,帮你生成第一版设计文档、接口说明、时序图
- 你只需要做校对、补充和删减
- 把文档放回仓库里,后面再让 AI 做 Code Review、写新功能时,就可以引用这些文档
这就是图中的那个「用 AI 生成文档,反哺 AI 的正向飞轮」。你越肯定标准化,AI 越好用,AI 越好用,你越愿意做标准化。
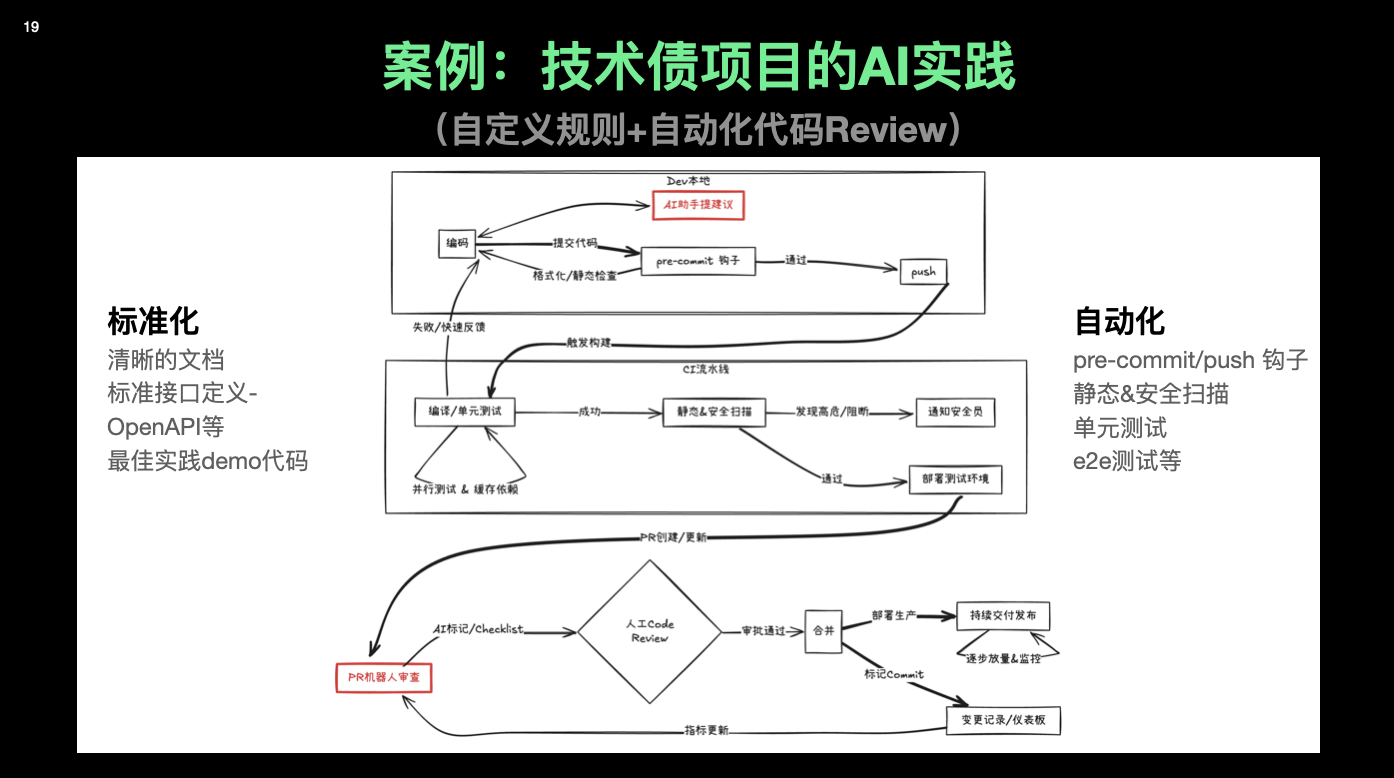
2. 自动化:让机器先说一遍「对 / 不对」
第二件事是降低验证成本。
最典型的例子就是 pre-commit hook。以前你要在项目里加一个像样的 pre-commit:先要搞懂这个工具的原理:是 Git Hook?是独立的 CLI?,再研究生态:选哪个框架、怎么写配置,如果项目主语言你不熟(比如钩子本身是 Python),还要折腾一堆环境问题,最后再想办法让所有人都装上、用起来。一个没接触过的人,三五天是很正常的成本,所以很多团队干脆就放弃了。
现在的路径可以变成这样:
- 打开 AI 工具,说清楚你的代码栈、仓库结构、想检查的内容(格式、lint、简单测试)
- 让它给你生成一套可运行的 pre-commit 配置
- 你照着一步步执行,有问题就让它继续 debug
- 一个小时左右,大多数仓库都能跑起来第一版
坑仍然存在,但是踩坑的时间成本被 AI 降下来了。原来因为门槛太高所以没人做的工程化改造,现在可以被视为一个「甜点任务」。
同理,你可以用类似方法,把这些东西慢慢补齐:
- 自动化测试(单元测试 / e2e)
- 静态代码检查、依赖安全扫描
- PR 模板、机器人自动评论
- CI/CD Pipeline 的优化(比如「10 分钟法则」)
我在一个技术债很重的项目上就这么干过。先用 AI 帮忙总结出一套「我们自己的代码规则」,再写脚本,让 AI 根据这些规则自动扫 PR、自动提建议,人类 Review 只需要关注真正困难的设计问题。几个月下来,Review 压力肉眼可见地下来了,线上 Bug 的数量也稳定下降了。
如果你是技术管理者,可以把它理解为:
先把规则讲清楚,再让 AI 帮你打分,而不是反过来。
四、人类是一个「上下文很小」的 LLM:为什么会更累?
还有一个是很多高强度使用 Agent Coding 的工程师会遇到的问题:「明明 AI 写了 40% 的代码,为什么我反而比以前更累?」
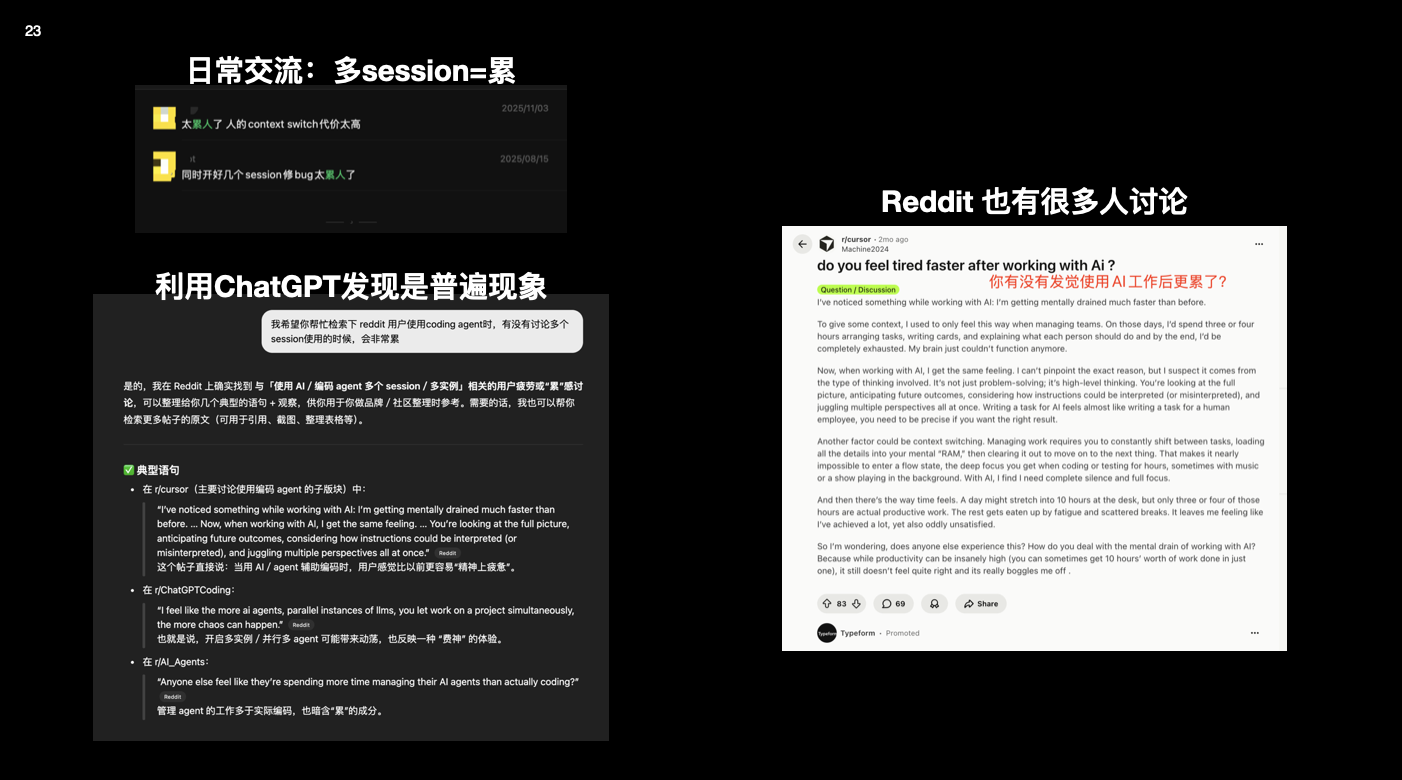
我自己也经历过这个阶段。任务丢给 AI 之后,我一整天都在这几个状态里切换:给这段逻辑写 prompt,看它生成的代码对不对,觉得不放心,再丢给另一个模型二次确认,同时还要盯着几个 PR、几个 Issue、几个聊天窗口。
后来我在 Reddit 和 ChatGPT 的对话里发现,这几乎是个群体现象。
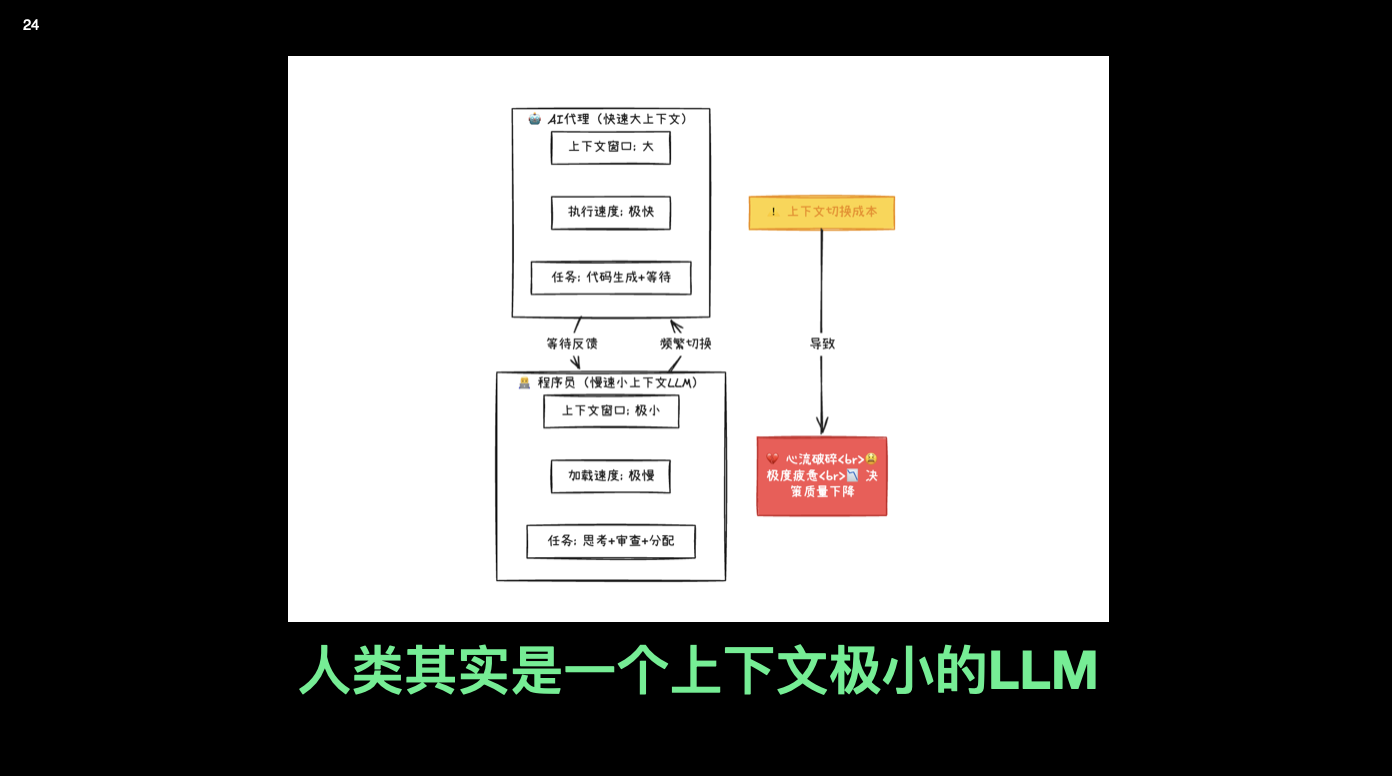
抽象来看,我把人类大脑也画成一个 LLM,计算力很强,但是上下文窗口极小,对频繁切换任务特别不友好

再加上心理学里说的「心流」(flow):研究表明,知识工作者如果能在高认知负荷、少干扰的任务上保持较长时间的心流状态,产出会显著提高。
而我们现在的使用方式,恰好是心流的反面:
- 一天开十几个 Chat 窗口,
- 同时搞登录、搞费用结算、搞部署脚本,
- 不停地在不同上下文之间来回切
结果就是:AI 的计算力上来了,我们自己的「调度开销」爆炸了。
我自己的「时分复用」小方案
为了不被这种调度开销拖垮,我给自己设了一些很简单的约束。
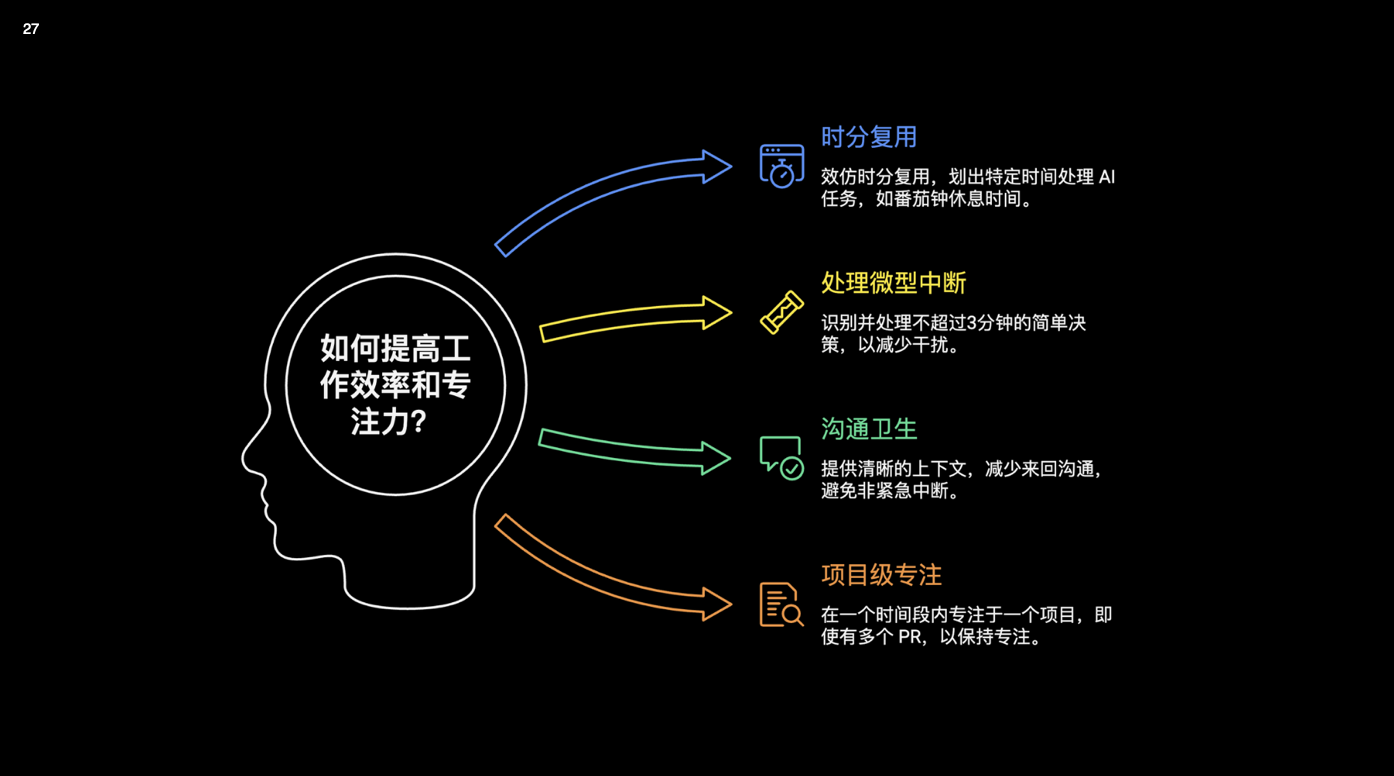
- 时间分层。一天拆成几块深度工作时间和沟通时间;深度工作时间只搞一件事:比如只盯一个模块或一个 PR;AI 在旁边当助手,但我尽量不在这一个小时里切另一个大主题
- 时分复用 AI。一段时间专门用来写 prompt、定义任务,把「我要干什么」说清楚;然后开几个 Agent 让它们去跑,自己去做别的事情;下一段时间再集中验收这些产出,而不是生成一段就立刻审一段
- 三分钟原则。能在三分钟内处理完的小事(看一眼就能决定的合并请求、简单问答),就当场解决;超过三分钟的,攒到下一次深度工作窗口再说
- 沟通卫生。不管是和同事还是和 AI,说问题的时候尽量把背景、目标、约束和验收标准一起写清楚;很多来回扯皮、反复问答,其实都是因为第一句没讲明白
- 项目级专注。在某一段时间,只给自己一个「主线项目」;即使手上同时有三个大项目,也尽量在一天里只推进一个为主,其他两个只做轻量维护
这些习惯看上去很「鸡汤」,但在 AI 时代其实是很硬核的工程实践:
因为你要承认一个事实:你的注意力,才是这个系统里最稀缺的资源。
如果你是管理者,可以顺着再问一句:
「我设计的流程,是在放大大家的心流,还是在用各种会议、工具、通知不断打断它?」
五、两条可能很多年都不过时的原则
写到最后,我想用 PPT 中总结的两条原则收个尾。
原则一:瓶颈已经从「生成」转移到「验证」

写代码本身已经不再是最耗时的部分:
- 生成初稿:AI 很快
- 真正耗时间的是:验证正确性、性能、安全性、可维护性
对个人来说,这意味着:
- 把更多时间花在写测试、设计监控、建立回滚机制上
- 学会用 AI 来参与验证,生成测试、辅助 Review、分析错误日志,而不只是让它写新代码
对团队来说,这意味着:
- KPI 里不要只看「AI 写了多少行代码」
- 更应该看:Bug 修复的 lead time 有没有变短?回滚一次要付出多大代价?新人接手模块要多久能上手?
原则二:上下文为王(Context is King)

AI 的能力上限,很大程度上取决于你给它的上下文。 比如,你有没有把业务背景、技术约束、决策过程写出来? 项目里有没有可复用的接口设计、术语表、测试用例、决策记录?
对个人来说,可以从这几件小事做起:
- 不要只丢一段代码给 AI,多写几句背景说明
- 把模糊需求拆成几个小目标,逐步让 AI 完成
- 多用例子,少用形容词
对团队来说,这其实是一整套很具体的工程动作:
- 先统一代码风格、目录结构和接口契约
- 再把 Spec、/design、/api、/tests 这些东西写进仓库
- 最后用自动化接管「对 / 不对」的判断,让这个判断尽量机械和可复用
如果只记住这一篇文章的一句话,我希望是:
AI 写代码的水平,往往就是你提供上下文的水平。
最后:给三类读者的一点小建议
- 还没开始用 AI Coding 的开发者。不要从最难的核心模块开始,先找一个小小的甜点区。写一组 CRUD、写几条测试、写个迁移脚本。先把「值不值」那条式子算顺。
- 已经高强度使用 AI 的工程师。可以试着别再纠结「它写得准不准」,而是花时间设计更清晰的上下文,再搭一套验证流程。挑一个模块,当成实验田,用上文这些办法,把标准化和自动化做一遍。
- 技术管理者。自己最好先亲手用一用 AI Coding,再谈团队推广。同时把视野从「个人速度」抬到「协作和工程流程」上:让 AI 不只是一个写代码的工具,而是整个生产流水线里的一个环节。
希望等你哪天回头再看这篇文章时,工具也许已经又换了一轮。但只要这些心态和方法还在,它们就还能帮你少走一点弯路。
延伸阅读与参考引用
- Codex 官方最佳实践文档(OpenAI Prompt Engineering 指南):https://platform.openai.com/docs/guides/prompt-engineering
- Claude Code 官方最佳实践文档(Best practices for agentic coding):https://www.anthropic.com/engineering/claude-code-best-practices
- yage.ai 博客(AI Coding 实战案例):https://yage.ai/
- Spec Kit(GitHub 开源规格模板集):https://github.com/github/spec-kit
- OpenSpec 项目(开放式规格与工具链):https://github.com/Fission-AI/OpenSpec
- 微软 20%–30% AI 代码占比访谈(Satya×Zuck):https://www.businessinsider.com/ai-code-meta-microsoft-google-llamacon-engineers-2025-4
- 谷歌「>25% 新代码 AI 生成」财报电话会(Alphabet 2024 Q3 Earnings Call):https://abc.xyz/investor/events/event-details/2024/2024-q3-earnings-call/
- Aikido 报告与 DevOps.com 解读(全球生产代码约 24% 为 AI 生成):https://devops.com/survey-surfaces-rising-tide-of-vulnerabilities-in-code-generated-by-ai/
- Robinhood 约 50% 新代码由 AI 生成(20VC 访谈转引):https://www.efinancialcareers.com/news/robinhood-ai-coding
- GitHub×Accenture 企业研究(Copilot 建议接受率约 30%):https://github.blog/news-insights/research/research-quantifying-github-copilots-impact-in-the-enterprise-with-accenture/
- 微软研究院论文:The Impact of AI on Developer Productivity(受控实验 55.8% 提升):https://www.microsoft.com/en-us/research/publication/the-impact-of-ai-on-developer-productivity-evidence-from-github-copilot/
- 《深度工作》作者主页:https://www.calnewport.com/books/deep-work/
- 番茄工作法官网(The Pomodoro® Technique):https://www.pomodorotechnique.com/
- Getting Things Done 官网:https://gettingthingsdone.com/
公开引用对应关系
这几组数字大致是这样来的:
20%–30% 微软 / 谷歌占比
Satya Nadella 在 2025 年 Meta LlamaCon 的对谈里提到,微软内部大约有 20%–30% 的新代码已经由 AI 生成。
Sundar Pichai 则在 Alphabet 2024 Q3 财报电话会上说,谷歌这边「超过四分之一」的新代码来自 AI,最后都会经过工程师评审。
(见 Business Insider、Alphabet Q3 Call)。24% 平均值 vs 50% 激进团队
Aikido Security 的报告给了一个「全行业平均」的刻度:生产环境代码里,大约 24% 是 AI 写的,约 1/5 的严重事故和 AI 代码有关。
在另一端,Robinhood CEO 在 20VC 播客里提到,内部一些比较激进的团队,差不多已经做到「一半新代码来自 AI」。
(见 DevOps.com、eFinancialCareers)。30% IDE 建议接受率
GitHub × Accenture 的联合研究里提到,在企业场景下,开发者大约会接受 30% 左右的 Copilot 建议,
而被接受的建议中,大约 88% 的字符会保留到最终版本。
(见 GitHub Blog)。55.8% 受控实验效率提升
微软研究院在论文《The Impact of AI on Developer Productivity》里做过一个比较干净的对照实验:
只引入「有 Copilot vs 无 Copilot」这一项变量,试验组完成任务的速度快了约 55.8%。
(见 Microsoft Research)。
上面这些数字,主要是在标一个量级:
它们回答的是「AI 写了多少代码」「建议被采纳的比例」「只上 Copilot 一项带来的效率提升」这类问题。
文中我提到的 /spec、/design、/api、/tests 等「spec‑kit」做法,本质是把项目的上下文打磨干净一些。
这些工程实践不在上述受控实验的变量里,所以论文里看不到它们的名字,但在真实项目里,通常会让 AI 生成的命中率和长期可维护性再往上抬一截。
版权声明
ai-coding-handbook © 2025 by Miss-you
本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议(CC BY-NC-SA 4.0)进行许可。
您可以自由地:
- 共享:在任何媒介以任何形式复制、发行本作品
- 演绎:修改、转换或以本作品为基础进行创作
惟须遵守下列条件:
- 署名:您必须给出适当的署名,提供指向本许可协议的链接,同时标明是否(对原始作品)作了修改。您可以用任何合理的方式来署名,但是不得以任何方式暗示许可人为您或您的使用背书。
- 非商业性使用:您不得将本作品用于商业目的。
- 相同方式共享:如果您再混合、转换或者基于本作品进行创作,您必须基于与原先许可协议相同的许可协议分发您贡献的作品。
详情请参见:https://creativecommons.org/licenses/by-nc-sa/4.0/
评论