我是 yousa,一名关注 AI 落地策略的大厂资深研发。
本文用 15 分钟告诉你可执行的判断标准与 5% 成功样本的落地清单。你将能学习到:① 判断 95% 的成因是否适用于你;② 明确 Buy/Build 的前提;③ 72 小时内验证一个后台场景。
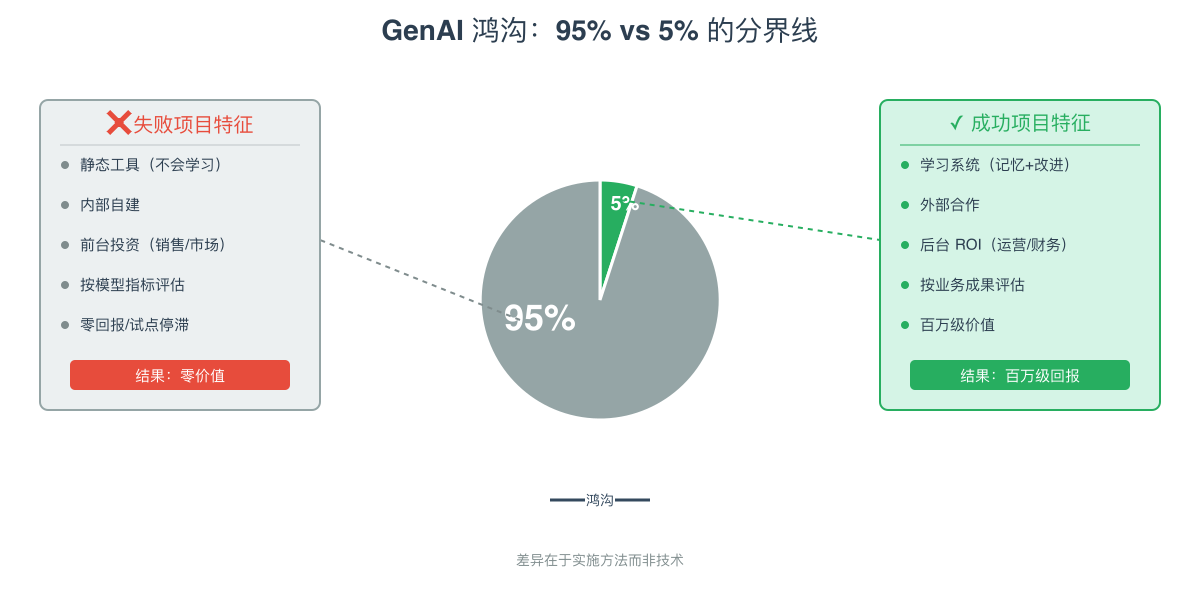
当前全球 95% 的企业为 GenAI(生成式 AI)投入了数百亿美元,却普遍未见成效,为什么?报告认为,原因不在模型能力,而在于采购方的实施方法。
MIT NANDA 追踪 300+ 项目发现:那 5% 的成功,靠的是三件反常识的事——Buy(外部合作)而非 Build(内部自建)、优先后台 ROI 而非前台、按业务成果而非模型指标评估。
本文结构:
- 第一部分:报告核心发现 - 95% 失败的根源在哪?5% 成功的做对了什么?
- 第二部分:可信度验证 - 这个结论靠谱吗?四份研究的共识与分歧是什么?
- 第三部分:实践清单 - 如果你现在就要落地 GenAI,应该做什么、问什么?
第一部分:报告核心发现
高采用率 vs 低转型效果
企业在 GenAI 上已投入数百亿美元。但在 2025 年 1–6 月采访期内,95% 的受访组织并未看到 P&L(损益)改善。
相比之下,那 5% 与现有工作流深度集成的项目创造了超百万美元价值。这些价值主要来自减少外部支出——取消 BPO 合同、削减外部代理费。
四种 GenAI 鸿沟模式
报告将“GenAI 鸿沟”归纳为四类:
- 有限颠覆:八个主要行业中,仅科技与媒体出现些许可衡量收益,其他行业无明显收益。
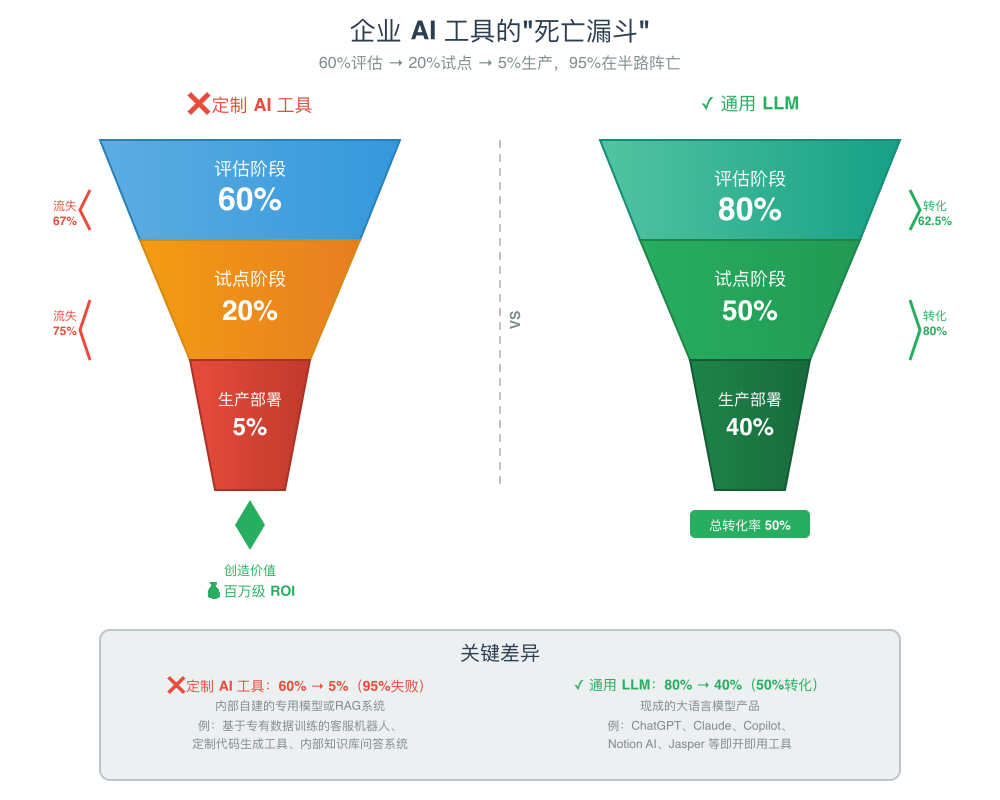
- 企业悖论:大型企业试点多、投入大,但成功率极低。它们难以将定制化 GenAI 工具转化为规模化生产部署,成功率远低于中型市场公司。
- 投资偏见:超过 50% 预算分配到销售/营销;但高 ROI(投资回报)往往来自运营与财务等后台领域。
- 实施优势:外部合作采购(Buy)的落地成功率显著高于内部自建(Build)。
GenAI 系统的学习能力是关键
AI 落地的拦路虎不在基础设施、法规或人才,而是 GenAI 系统“不会学习”。系统记不住上下文,也接不住现有流程。做得好的组织把 AI 与流程深度集成,并用反馈让系统持续改进。
企业用户做简单任务更偏爱 ChatGPT 等通用 LLM;一到关键任务,因缺乏记忆便弃用。70% 用 AI 处理邮件、摘要、基础分析;遇到高风险工作(客户管理、多周项目),90% 仍交给人,即便是初级岗位。
成功组织的共同特征
报告认为跨越 GenAI 鸿沟的 5% 组织有四个特征:
- 策略:优先外部合作(Buy),少自建(Build)。按运营结果而非模型基准评估。要求工具可定制、能与现有流程深度集成。
- 技术:只选具学习与记忆的 Agentic AI。系统需从反馈持续学习、保留上下文、随时间改进,弥补“学习鸿沟”。
- 组织:把采用权下放给一线经理与领域专家(Prosumers)。自下而上推进,确保方案贴合实际流程。
- 投资:把钱投向后台运营以拿到实效。相比销售/营销,运营、财务、采购的自动化产出更快、更可持续,主要体现在减少外部支出(如 BPO 合同)。
因果链:95% 未见 P&L → 后台 ROI 更高 → Buy > Build → 学习能力为胜负手
第二部分:可信度验证
看到"95% 失败"这个数字,你可能和我一样的第一反应是:这会不会太悲观了?
毕竟市面上不少报告都在讲 GenAI 如何提升效率、创造价值。为什么 MIT 的结论这么极端?是样本问题、方法论问题,还是真的就是这么残酷?
让我用三个方法来验证这份报告的可信度:方法论审查、交叉验证四份同类报告、提炼共识。
方法论审查
报告是使用什么样的方式进行调研的?
重新精读完报告后,我发现本报告主要用这三种方法调研:
- 半结构化高管/一线访谈(52 个组织,附录有完整访谈提纲:投资/建购决策、ROI 指标、规模化障碍等)
- 轻量问卷(四个主要行业会议上收集到的 153 位高管的调查问卷)
- 系统地回顾 300+ 公开披露的 AI 项目
调研方式有一定说服力,那么业界对于该报告的看法是怎么样的呢?学界对于该报告有哪些争议呢?
交叉验证四份同类报告
近 1 年以来,类似主题的报告结论和研究方法与本报告有什么异同?
我用 GPT 和 Google 检索,从「问卷/题型、指标定义、样本构成」等角度对比,搜索到了「IDC、McKinsey、Snowflake」等对于该问题做的研究。
四份报告的简要对比如下:
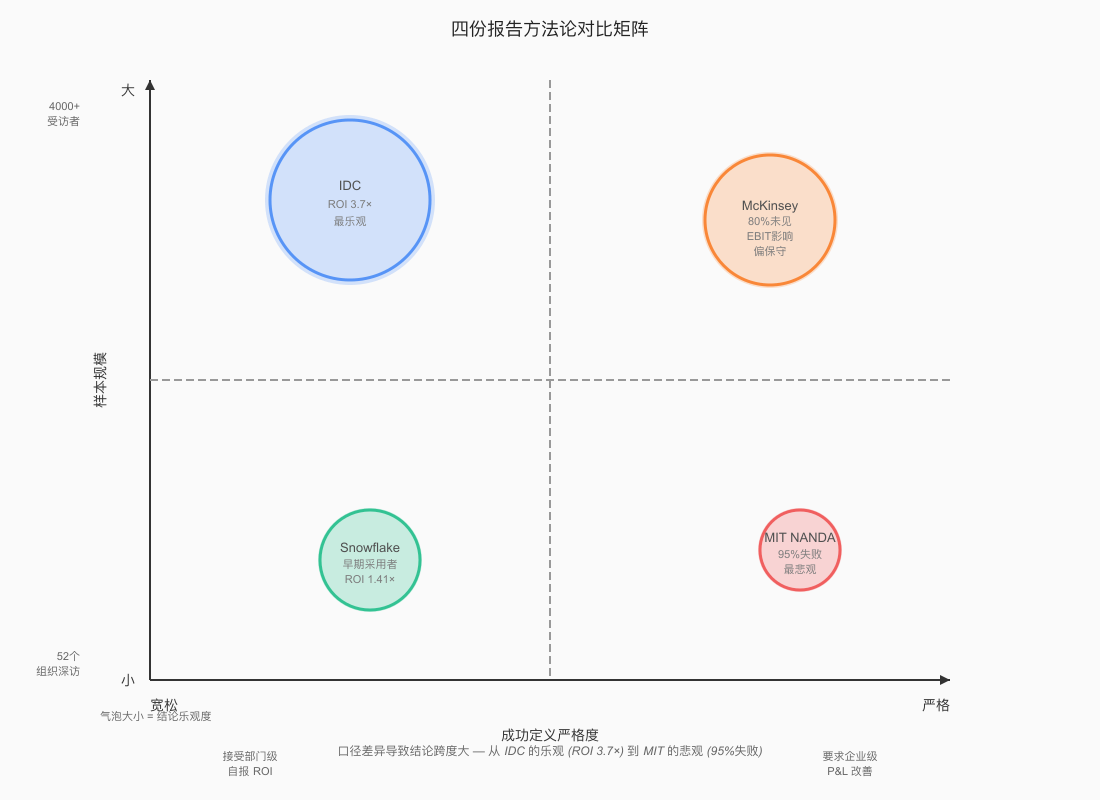
MIT 最悲观 (95%失败),IDC 最乐观 (ROI 3.7×); 关键差异在于"成功定义"——MIT 要求企业级 P&L 改善,IDC 接受部门级自报 ROI。
详细对比表格:
| 机构 / 报告 | 问卷题型(示例) | 指标定义(ROI / EBIT / 成本 / 收入口径) | 样本构成 |
|---|---|---|---|
| IDC(Microsoft 赞助)《2024 Business Opportunity of AI》 | 典型问题:“贵组织每在 GenAI 上投入 1 美元,ROI 约为多少倍?”;并询问各职能“当前在用 / 24 个月内计划在用”等采用题。(143485449.fs1.hubspotusercontent-eu1.net) | ROI=受访者对“每投入 1 美元的回报倍数”的自报估算;给出全球均值 3.7×、行业/地区拆分与“领军者 10.3×”。未设置企业级 EBIT 归因口径;成本/收入以用例层面成效叙述为主。(143485449.fs1.hubspotusercontent-eu1.net) | 时间/版本:InfoBrief,2024-11(IDC #US52699124);样本:全球 4,000+ 决策者(正文页);ROI 图表样本 n=3,343(全球;另给各地区 n);调研时间:2024-08;赞助:Microsoft。(143485449.fs1.hubspotusercontent-eu1.net) |
| McKinsey《The State of AI: How organizations are rewiring to capture value》(2025-03) | 多维组织与成效问卷:谁负责** AI 治理**、是否重构流程、业务单元收入/成本过去 12 个月变化;以及企业层面 EBIT 归因问题。 | EBIT:以“过去 12 个月企业层面 EBIT 可归因于 genAI 的占比”衡量;文中指出“>80% 尚未看到企业级 EBIT 的‘可感知影响’;17%称 ≥5% EBIT 可归因于 genAI”;同时统计业务单元层面的收入上升与成本下降(功能维度)。 | 样本:1,491 名参与者;在线问卷时间 2024-07-16~31;覆盖 101 个国家、各行业/规模(其中 ≥$5 亿营收企业比例较高)。报告发布日期:2025-03。 |
| Snowflake × ESG《Radical ROI of Generative AI》(2025-04) | 典型题:是否已量化 ROI、每 100 万美元投入的回报额;当前目标与落地挑战(数据准备、治理、成本超预期等)也有定项选择题。(Intelligent CIO) | ROI:两类口径并用——“已经回本(正 ROI)”占比与已量化的平均 ROI($1→$1.41,即 41% ROI);未设企业级 EBIT 归因指标。样本核心为早期采用者(production 中使用商用/开源模型)。(Snowflake) | 样本/时间窗:共 3,324 受访组织,其中** 1,900** 为“早期采用者”;调研期 2024-11-21~2025-01-10;覆盖 9 国;发布:2025-04-15(新闻稿)。(Intelligent CIO) |
| MIT Media Lab(NANDA)《The GenAI Divide: State of AI in Business 2025》(初稿,2025-07) | 多方法:①半结构化高管/一线访谈(附完整访谈提纲:投资/建购决策、ROI 指标、规模化障碍等);②轻量问卷(4 大会议场景回收);③系统性案头回顾(300+ 公开项目)。 | 成功/ROI 定义:将“成功”界定为越过试点、形成可度量 KPI 的部署;ROI 影响在试点后 6 个月评估,并按部门规模做校准;总论断称“约 95% 的组织未获得可衡量的 P&L 回报,仅 5% 的集成式试点产生了百万级价值”。(附方法与局限披露。) | 研究期:2025-01~06;样本:52 家组织深访、153 位高级管理者问卷、300+ 公开实现复盘;产出性质:与 MIT NANDA 合作制作(方法/偏差在附录披露)。 |
我来简单解读上述表格,偏主观,仅供参考:
IDC & Snowflake:乐观派 多为用例/部门的自报 ROI,样本偏向已采用者和早期采用者,结论偏乐观。
McKinsey:保守派 强调企业级 EBIT 归因,结论更保守。
MIT NANDA:严格派 采用短窗(6 个月)和严格的成功定义。样本量虽小,但更关注实际 P&L 收益。标准高、收益窗口短,加上 AI 的 J 型收益曲线还未显现,导致结论偏悲观。
核心差异在哪? 口径差异是主因——“乐观 vs. 审慎"的衡量标准不同。同样,样本构成的差异(已采用者 vs. 全体企业)也导致了结论的不同。
综上,我认为本报告 5% 的成功率可能过于悲观。但 GenAI 工具对企业的收益提升不明显、落地困难,这确实普遍存在。
提炼共识
既然各报告结论差异这么大(从 IDC 的 ROI 3.7× 到 MIT 的 95% 失败),那我们应该相信谁?
相信共识,质疑非共识。
这四份报告立场、方法、样本各不相同:IDC 乐观、McKinsey 保守、Snowflake 关注早期采用者、MIT 标准严格。但当它们在某些关键问题上不约而同地得出相同结论时,那些共识才是我们真正应该关注的。
我整理了一下,有四个共识与两个非共识:
| 类别 | 主题 | 要点/结论 | 例证/说明 |
|---|---|---|---|
| 共识 | 工作流再设计与深度集成 | 把 GenAI 当作流程重构工具,而非“叠个助手” | 麦肯锡对 25 个属性做关联分析,发现“重构工作流”对企业层面 EBIT 影响的相关性最大 |
| 共识 | 数据平台能力很重要 | 可扩展算力与存储、实时/批集成、分析能力、数据共享易用性、安全与治理 | Snowflake×ESG 的受访“早期采用者”在平台选型里打分最高的项之一 |
| 共识 | 针对于具体业务改造(RAG/微调/多模型) | 训练/增强/微调是“必做功课”,其提升了上下文与任务相关性 | 90%+ 受访早期采用者进行训练/增强,80%+ 用自有数据微调;大规模采用 RAG |
| 共识 | 清晰的度量/KPI 与变革推进 | 将解决方案嵌入业务流程、开展角色化培训、建立反馈回路持续改进、用 KPI 跟踪采用率与 ROI 等 | 麦肯锡提出的“规模化最佳实践”集合的一部分 |
| 共识 | 人才与技能 | “流程+培训+变革管理”与成效显著相关,缺乏技能是推进的头号障碍 | IDC 报告 |
| 非共识 | Agentic AI 的记忆/学习能力 | 胜负手 | Agentic + Memory Frameworks |
| 非共识 | 采购 vs 自建(Buy vs Build) | 外部合作成功率更高;自研自建更易失败 | 适用于 GenAI/Agentic AI 采买场景 |
总结一下,我认为,这篇报告包括调研部分置信度高——非共识部分可以选择性接受。
基于上述分析,我对「报告要点总结」中的 1-2 部分评估置信度(0–100),仅供参考:
| 模块 | 判断点 | 置信度(0-100) | 依据/理由 |
|---|---|---|---|
| 高采用率 vs 低转型效果 | 95% 未见 P&L 改善;5% 深度集成项目百万级价值 | 70 | 多报告在企业级 EBIT 上结论偏保守;短窗+严格成功定义致比例偏低,但方向成立;价值主要来自外部支出下降 |
| 四种 GenAI 鸿沟模式 | 有限颠覆:仅科技/媒体见明显收益 | 95 | 行业差异与样本支持,但其他行业亦有零星成效,证据仍在积累 |
| 四种 GenAI 鸿沟模式 | 企业悖论:大企业试点多但难规模化 | 90 | 多来源指向治理/流程改造不足导致推进受阻;中型公司偶有优势但非定律 |
| 四种 GenAI 鸿沟模式 | 投资偏见:预算偏销售/营销,高 ROI 在后台 | 100 | 运营/财务自动化更快显现可持续 ROI,与多报告一致 |
| 四种 GenAI 鸿沟模式 | 实施优势:Buy > Build | 95 | 能力与时间窗相关,外部合作更易落地;但强研发组织可例外 |
第三部分:实践清单
理论分析完了,那 5% 成功的组织到底做对了什么?
前面两部分我们验证了报告可信度、梳理了四份研究的共识。但如果你现在就要评估一个 GenAI 工具、或者推动一个落地项目,具体应该怎么做?
这一部分,我从报告中提炼了最有价值的实践案例和行动清单。按"构建者”、“购买者”、“企业主"三个角色分类,告诉你每个角色应该关注什么、做什么。
成功案例:节省在哪?
报告中 5% 成功的组织,具体在哪方面成功了?我总结出三种类型:
- 替代业务流程外包 (BPO Elimination):在客户服务和文件处理等领域,通过 AI 自动化,每年可以节省 200 万至 1000 万美元的 BPO 合同费用。
- 减少代理机构支出 (Agency Spend Reduction):在外部创意和内容制作方面,AI 工具的应用使得公司的代理费用减少了 30%。
- 节约外包风险管理成本:一家金融服务公司通过 AI 自动化风险检查,每年在外包风险管理上节省了 100 万美元。
最佳实践:三类角色清单
作为 AI 工具公司或采购 AI 工具的企业,报告中哪些点最重要?
我整理了构建者、购买者和企业主的最佳实践要点:
| 角色 | 原则 | 关键动作 | 预期收益 |
|---|---|---|---|
| 构建者 | 从“human-in-the-loop”开始,逐步自动化 | 先 HITL(human-in-the-loop) 增强;设人工校正阈值;性能达标再下放给自动化 | 风险可控;从真实决策中学习;稳定性提升 |
| 构建者 | 为特定工作流程定制 | 微调专有数据;与现有系统(如 Salesforce/ServiceNow)集成;定制 UI | 任务相关性更高;落地成功率提升 |
| 构建者 | 设计反馈循环 | 采集纠错与结果;在线学习/批量重训;闭环改进 | 随时间持续改进;错误率下降 |
| 构建者 | 优先信任与透明度 | 可解释;允许人工覆盖;提供性能与边界文档/SLA | 采用率提升;组织阻力下降 |
| 购买者 | 小步快跑,快速迭代 | 选小用例做试点;阶段评审;达标后扩域 | 降低试错成本;缩短验证周期 |
| 购买者 | 优先考虑集成 | 预构建连接器;开放 API;与厂商协作做定制集成 | 上线更快;维护成本更低;流程不中断 |
| 购买者 | 关注用户体验 | 终端用户参与评估;提供培训与支持;持续收集反馈 | 采用率与使用深度提升 |
| 购买者 | 衡量重要事项 | 与业务共建 KPI;跟踪生产率/成本/满意度/收入 | 可证明 ROI;便于争取后续预算 |
| 企业主/管理者 | 思维转变:像 BPO 客户思考 | 寻找深度定制、对业务结果负责的战略伙伴;要求深度共建 | 结果导向;避免“买工具不改流程” |
| 企业主/管理者 | 组织设计:授权一线,优先 Buy | 一线主导选型与推广;以外部合作起步;明确采用/成效责任 | 采纳率更高;落地更快;失败率下降 |
| 企业主/管理者 | 投资策略:优先后台 ROI | 聚焦运营/财务/采购;以替代 BPO、削减外包为主 | 可持续 ROI;潜在年节省数百万美元 |
| 企业主/管理者 | 评估标准:重业务成果 | 共建 KPI(如资格审查提速、外部费用下降);试点前设阈值 | 可证明价值;便于争取预算与扩域 |
如果明天就要评估一个 GenAI 工具,你应该问供应商什么问题?
上面的最佳实践表格内容很多,但核心逻辑可以浓缩为三个问题——这三个问题能帮你快速判断一个 GenAI 工具是否值得投入:
- 它会记住我们的反馈并持续改进吗?
- 6 个月后会更懂我们的业务,还是和第一天一样?
- 供应商愿意按业务成果而非 license 数付费吗?
说明: 本文基于 MIT NANDA 项目 2025 年 7 月报告整理,并对比了 IDC、McKinsey、Snowflake 三份同期研究。置信度评估仅代表个人判断,非共识部分(如 Agentic AI、Buy vs Build) 可选择性接受。完整报告链接见文中引用。
附录:部分术语参考
核心概念
GenAI: 生成式人工智能 (Generative AI)。能够生成文本、图像、代码等内容的 AI 系统。2022 年末以来的 AI 变革主要围绕着 GenAI「LLM、扩散模型、生图生视频等」 Agentic AI / Agentic Web: 智能体 AI / 智能体网络。能够记忆、学习、并自主行动的下一代 AI 系统和由其构成的互联生态 LLM: 大语言模型 (Large Language Model)。如 ChatGPT、Claude 等基于深度学习的文本生成模型
财务与组织术语
P&L: 损益表 (Profit and Loss)。企业一定时期内收入、成本和利润的财务报表 EBIT: 息税前利润 (Earnings Before Interest and Taxes)。衡量企业运营盈利能力的关键财务指标,排除了利息和税收的影响 ROI: 投资回报率 (Return on Investment)。投资收益与投资成本的比率 BPO: 业务流程外包 (Business Process Outsourcing)。将非核心业务流程外包给第三方服务商 KPI: 关键绩效指标 (Key Performance Indicator)。用于衡量业务目标完成情况的量化指标
技术术语
RAG: 检索增强生成 (Retrieval-Augmented Generation)。通过检索外部知识库来增强大语言模型回答准确性的技术 Fine-tuning/微调: 使用特定领域数据对预训练 AI 模型进行二次训练,以适应特定任务的技术方法 HITL / Human-in-the-loop: AI 系统设计模式,关键决策点保留人工审核和干预 UI: 用户界面 (User Interface)。用户与软件系统交互的视觉和操作界面 SLA: 服务级别协议 (Service Level Agreement)。供应商对服务质量、可用性等的承诺标准 CRM: 客户关系管理系统 (Customer Relationship Management)。如 Salesforce 等管理客户交互和数据的软件平台
组织与人群
Prosumers: 生产型消费者。既是产品消费者,又能参与生产和改进的用户,这里指熟练使用 AI 工具并推动组织采用的员工 SMBs: 中小型企业 (Small and Medium-sized Businesses)
机构与框架
NANDA: 网络化智能体与去中心化架构 (Networked Agents And Decentralized Architecture)。MIT 提出的支持智能体互操作的基础设施框架 IDC: 国际数据公司 (International Data Corporation)。全球知名的 IT 行业研究与咨询机构 ESG: 企业社会责任评级公司 (Enterprise Strategy Group), 也指环境、社会和治理 (Environmental, Social, and Governance) 标准
评论